Exploratory Data Analysis
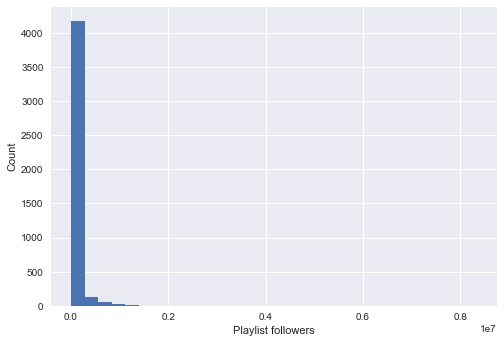
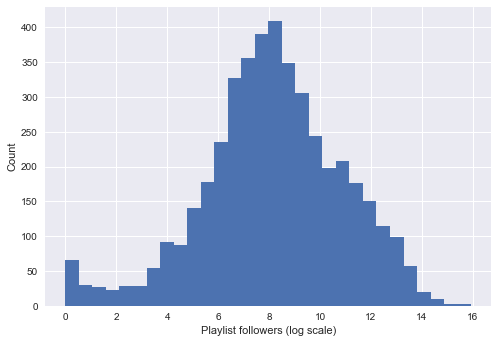
Distribution of predictors and number of followers
We generated a barplot of the average values of different audio features for different genres. In order for the plot to be more informative, we normalized the range of each feature to be (0, 1). The main idea between this visualization is to show that different genres have different profiles of audio features, which determined their uniqueness.
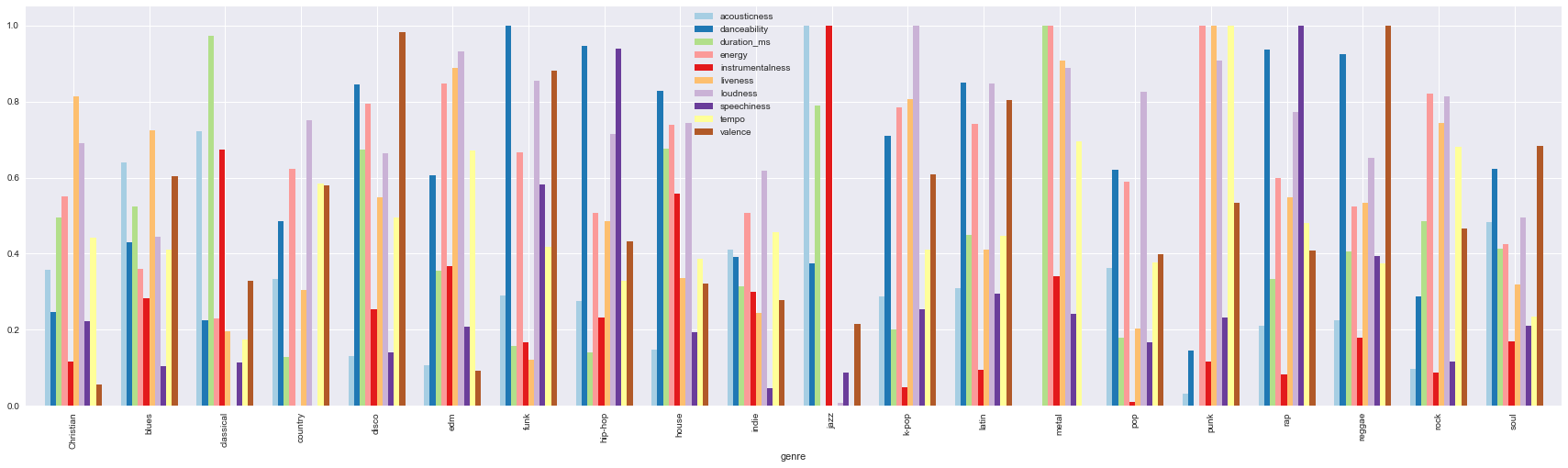
Figure 1. Average values of audio features for different genres
For example, funk music has high danceability, jazz music has high instrumentalness, hip-hop has high speechiness, etc. This tells us these audio features can be very distinguishing. We also want to understand the distribution of the response variable - number of followers for each playlist. Thus, we plotted a set of boxplots of followers for each genre. In general, pop, hip-hop, classical and rock have relatively higher median and variance.
We also want to understand the distribution of the response variable - number of followers for each playlist. Thus, we plotted a set of boxplots of followers for each genre. In general, pop, hip-hop, classical and rock have relatively higher median and variance.
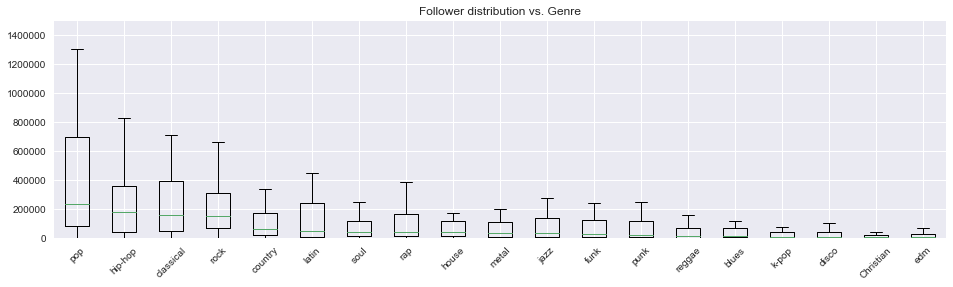
Figure 2. Distribution of number of followers for different genres
Relationship between predictors and number of followers
With an aim to identify useful predictors for building regression models, we plotted scatter plot of the number of followers with respect to different predictors. Here possible predictors include audio features of the tracks within the playlist, and the popularity of them (measured by how much it has been played on Spotify). However, as each song in a playlist can have a set of values, we will need some method of aggregation to construct playlist-level features. Here, we explored two ways, using mean to capture overall level, and using standard deviation to capture diversity within the playlist. In order to show clearer relationships, the graphs below might exclude some outliers that affect the visual.
When using mean as the aggregation method, we observe that some audio features, such as loudness and popularity (Fig 3), positively contribute to the number of followers. We also observed that instrumentalness is negatively correlated with number of followers. For tempo, it seems to have an interval that correlates more to high number of followers. This calls for feature engineering in subsequent steps, such as discretization of the tempo variable.
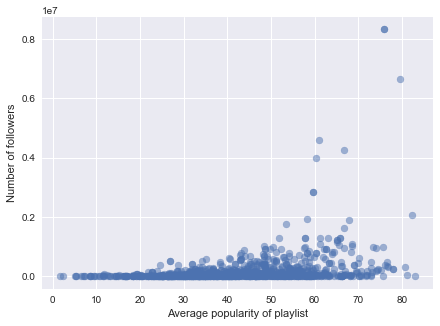
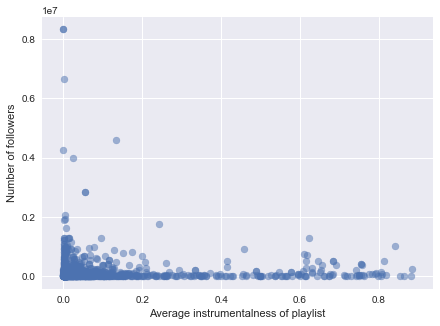
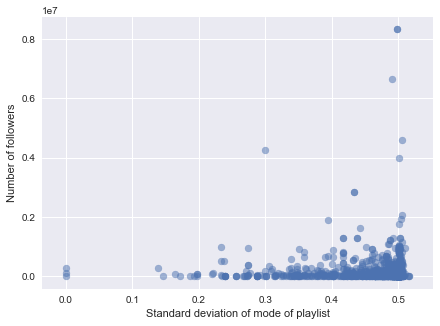
Figure 3. Scatterplots of number of followers against predictors. (left: average popularity, middle: average instrumentalness, right: standard deviation of mode)
When using standard deviation, we can capture whether feature diversity in a playlist has relationship with the playlist follower numbers. So if we observe skewness in the plot, it means that either diversity of homogeneity is favorable to gaining higher followers. We observe that when a playlist has diversity in mode is positively correlated with the number of followers. This makes sense as mode directly determines the mode of the song. A relatively large diversity of tempo also seems to give rise to high followers, as the distribution is right-skewed.
Relationship between predictors and number of followers for different genres
As in the end we need to generate playlist for a specified genre, the model should be able to adapt to different genres. Therefore, we want to explore that for playlist in different genres, whether there is interaction between genres and the predictors’ correlation with the number of followers. Thus, we created a heatmap shown below. Each cell represents the correlation between predictors (represented by vertical axis) in a particular genre (represented by horizontal axis) and the number of followers of the playlist.
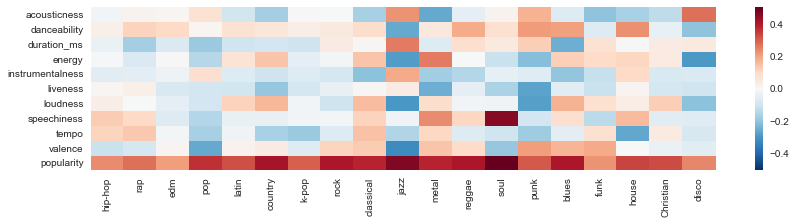
Figure 4. Heatmap of correlation of predictors with number of followers by genres
There is plenty of information in the heatmap. To name a few, popularity has positive correlation with followers across genres; speechiness is positively correlated with followers in soul music; valence is negatively correlated with followers in pop music; the correlation for different features is more bipolar in jazz, etc. This allows us to create interactions in the regression model to predict number of followers.